the Phat Distribution¶
In Search of Two Tails¶
Many phenomena are understood to exhibit fat tails: insurance losses, wealth distribution, rainfall, etc. These are one-tailed phenomenom (usually bounded by zero) for which many potential distributions are applicable: Weibull, Levy, Frechet, Paretos I-IV, the generalized Pareto, the Extreme Value distribution etc.
For two-tailed phenomenon, such as financial asset returns, there are only two, and decidedly imperfect, candidates:
Levy-Stable Distribion
the Levy-Stable is bounded in the range \(\alpha \in (0, 2]\) with \(\alpha = 2\) being the Gaussian distribution. Thus, the Levy-Stable only exhibits fat tails with tail index \(\alpha < 2\) and undefined variance.
Unfortunately, equity returns in particular are known to have both a second moment AND fat tails, meaning \(\alpha > 2\), which the Levy-Stable does not support.
Student’s T
the Student’s T is the most popular distribution for modelling asset returns as it does exhibit fat tails and it is power law-like.
unfortunately, the Student’s T only tends toward a power law in the extreme tails and so can still heavily underestimate unlikely events.
also, the Student’s T is symmetric and cannot accomodate different tail indices in either tail. Nor can the skewed Student’s T, which is asymmetric, but accepts only a single tail index.
we should note that an asymmetric Student’s T has been proposed to address this.
As a result of the seeming intractability of this problem, academics and risk managers often opt for a non-parametric or “tail-only” approach.
For instance, Papenbrock et al. 2016 and many others use the generalized Pareto to focus solely on VaR.
Nystrom and Skoglund (2002) proposed two-pareto tails with a Gaussian kernel density in the body.
These models are useful, no doubt, but perhaps we can do better.
the Double Pareto¶
The simplest approach to two-tailed power laws is two combine two Paretos, reflecting one so that it is left-tailed.
Note: going forward we will generally use the term “Pareto” to refer to the “Generalized Pareto”
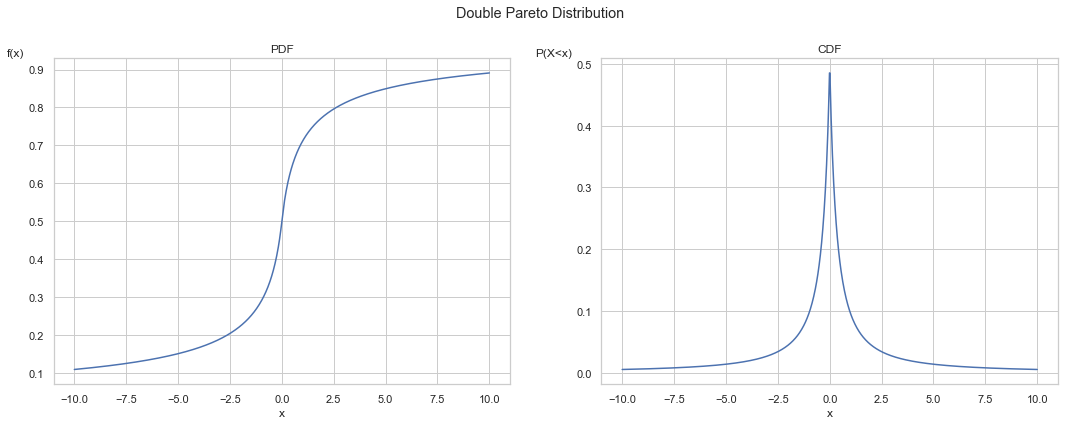
Below we can see both the CDF and PPF functions of the double Pareto track the product of its two components. The PPF chart has a logsym scale on the y-axis, which is awkward looking but allows log scale for both negative and positive values.
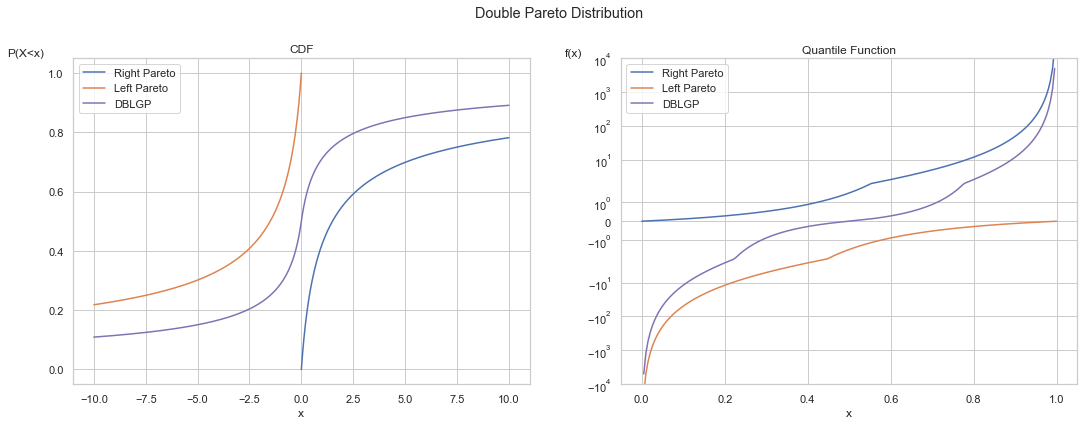
We can fit the double Pareto to S&P 500 equity returns, using the POT method. The result is the below, compared with the Student’s T:
[*********************100%***********************] 1 of 1 completed
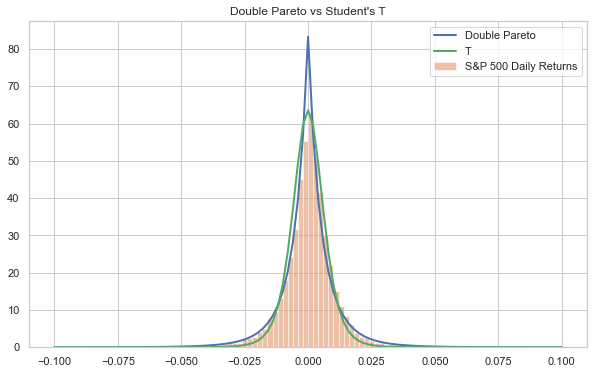
As expected, the double Pareto is a tighter fit in the tails, but it underestimates the shoulders and significantly overestimates the peak.
the CarBen Hybrid¶
As we saw above, the double Pareto performs well in the tails but is a poor model of returns in the body. One approach to addressing this issue is to just ignore it. Taleb would say all the impact is in the tails anyway, so the action in the body can simply be ignored. Fine, but if we can improve the performance in the body, this should improve our modelling.
Another approach is to combine two distributions: one for the body and one for the tail. Carreau and Bengio (2009) propose an approach for grafting a generalized Pareto distribution onto the tail of a Gaussian. The resulting Carben hybrid is a one-tailed distribution, with properties as follows:
described by 5 parameters
\(\mu\) and \(\sigma\) for the Gaussian
\(a\), \(b\), and \(\xi\) representing location, scale, and shape of the Pareto tail
as we’ll see, two necessary equalities reduces the number of free parameters to 3
the junction point between the two distributions is the location parameter, \(m\), of the Pareto tail, such that:
where:
the derivatives of each distribution at the junction point are also equal:
from (2) and (3) above, the location and scale parameters of the Pareto are (see Carreau for derivation):
where:
So, we have just the following free parameters to estimate:
for the gaussian: \(\mu\) and \(\sigma\)
for the generalized Pareto: \(\xi\), which is \(= 1/\alpha\), or the inverse of the tail index
a scaling factor, \(1 / \gamma\), is applied to both distributions such that the probabilities sum to 1. This scaling is also equivalent to the survival function in tail:
\(\gamma\) is computed directly as detailed in Carreau and Bengio (2008):
where:
Thus, the PDF for the Carben is given as:
where:
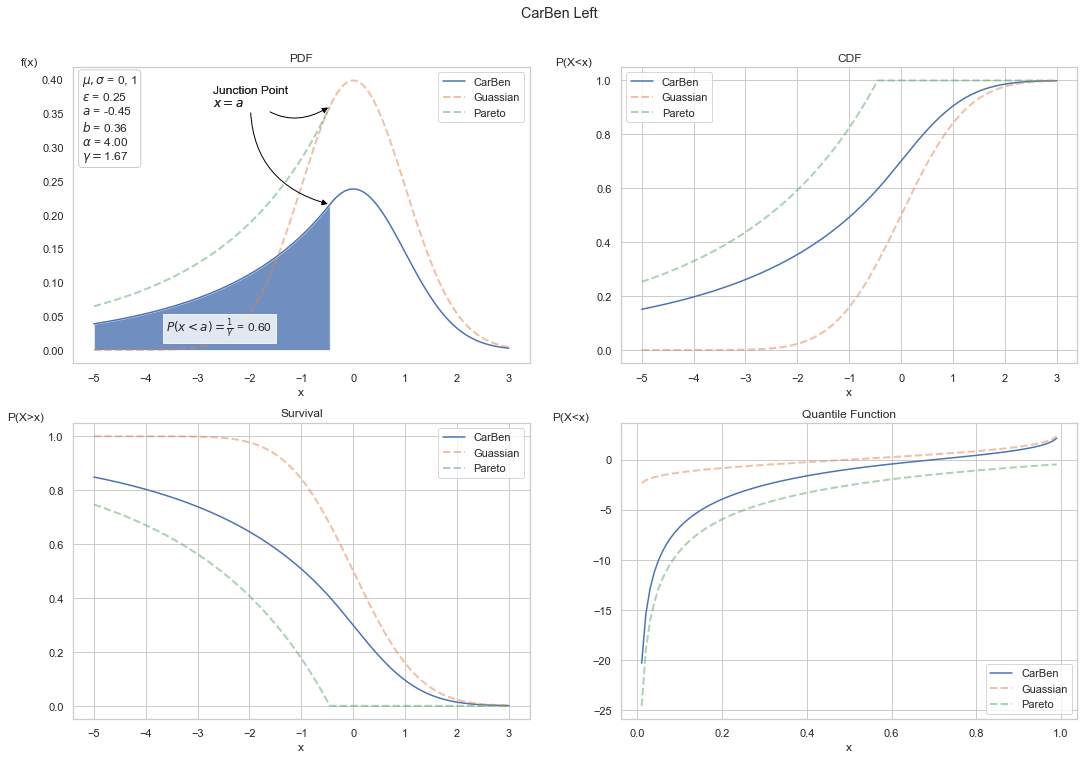
Below we show the statistical functions for the Carben with parameters:
\(\xi = 1/4\) (equivalent to \(\alpha = 4\))
\(a = 0\)
\(b = 1\)
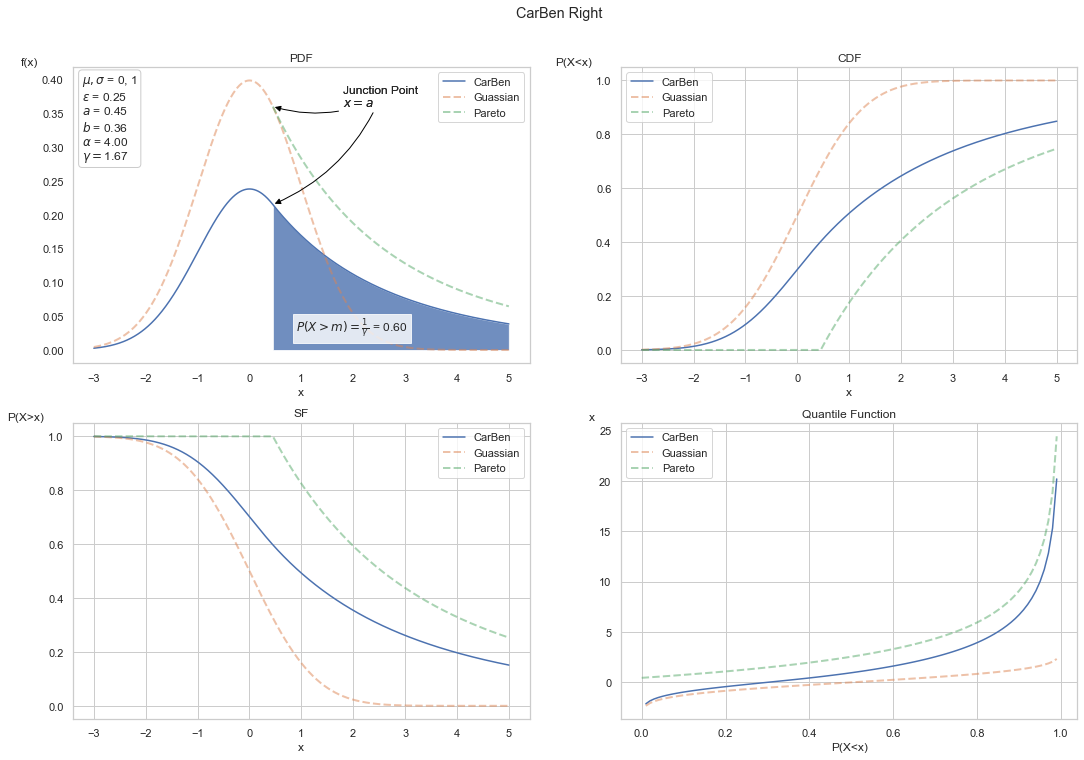
Reflecting the CarBen is trivial. One need only invert the Pareto location, \(a\), as well as the \(x\) values, resulting in the pdf as:
Pareto Hybrids with Asymmetric Tails: a Mixture Model¶
The CarBen is two-tailed, but thin-tailed in the left and fat-tailed in the right. We can arrive at a two fat-tailed model by mixing between a left-tailed and a right-tailed version. This was briefly suggested by Carreau and Bengio (2009) (though not implemented).
If both the left- and right-tailed CarBen’s have the same characteristics in the body (i.e. the Gaussian distributions are the same), the two will mix interchangeably between the junction points with the impact of mixing experienced mainly in the tails. The mixed model can be made symmetrical by providing the same shape parameter to both components, OR each tail can have a unique tail index as necessary. Thus, the distribution adds only one or zero new free parameters.
Mixing between continuous models is achieved simply as a weighted average in both the PDF, CDF, and, by extension, other characteristics:
The default weightings between the components is 50/50, i.e. \(w_i = .5\). Thus, we arrive at the Phat distribution as:
Below we show a symmetrical Phat, however, one with the Gaussian mean shifted positive and with a higher volatility, and so parameters are:
\(\xi_l = 1/5\)
\(\xi_r = 1/5\)
\(\mu = 2\)
\(\sigma = 2\)
[7]:
shape, mean, sig = 1/5, 2, 2
x = np.linspace(-10+mean, 10+mean, 1000)
dist1 = ph.Phat(mean, sig, shape, shape)
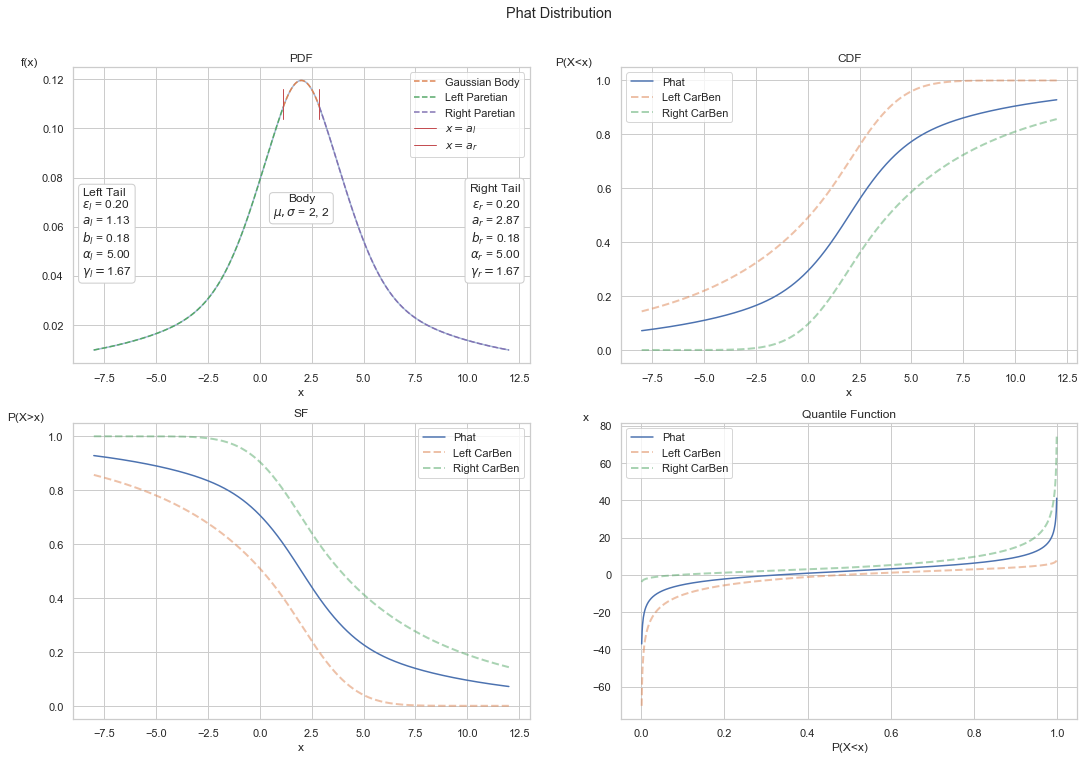
We can see above the properties shared between the left and right tails. The only statistical difference between each tail is the location, \(a\).
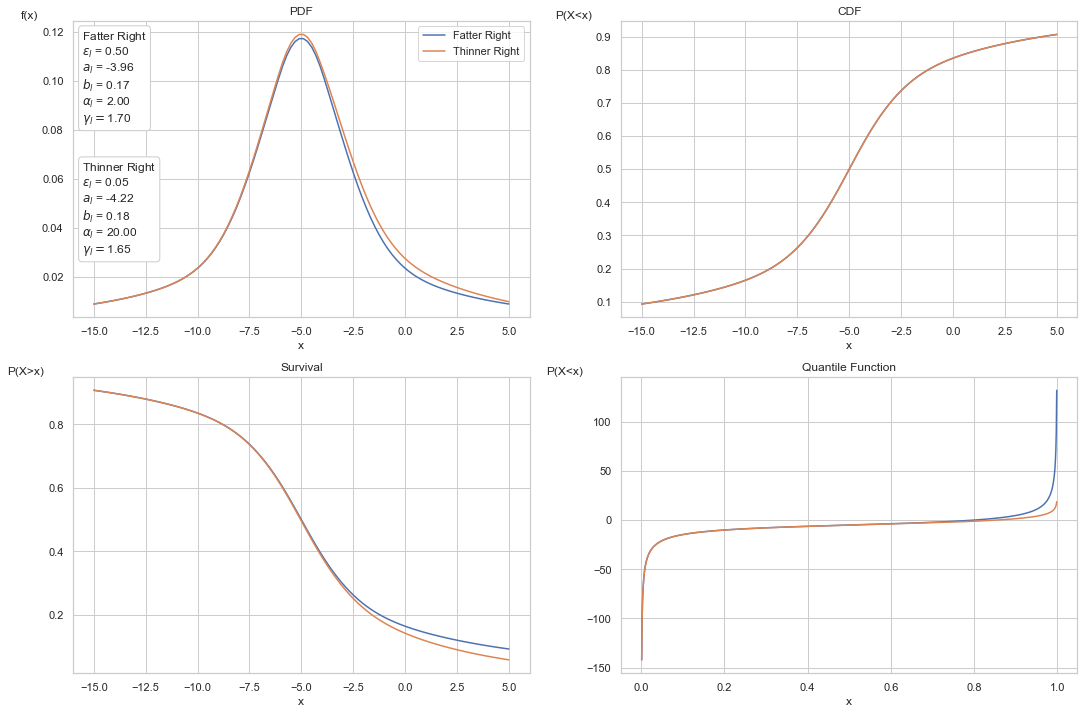
Below we show an example of two assymetric blends, one with a thinner left tail and one thicker. The left tails of both blends are identical. We can see the thicker tail twists lower near the body, of course, leading to a thicker tail in the extreme.
As we can see, simply by providing different left tail shapes, the tails end up with entirely different parameters overall.
Pitfalls¶
One important issue overlooked in the above analysis is the autoregressive nature of share prices. One underlying key assumption in the above is that each daily return is an independent observation. Instead, both the mean and volatility of daily returns seem to be correlated with recent historical observations. ARMA and GARCH models are often used to address this. Stochastic volatility models are also used, like the Heston, which exhibits random Gaussian variation with reversion to a long-term average volatility.
Mandlebrot (1996) proposed a fractal model with his characteristic fat tails and “long-term dependence” (also known as long-term memory), which allows for the influence of more distant historical observations.
There are different approaches that can be used to account for auto-correlation in fat tails.
a “declustering” technique was proposed in Coles(2001) that groups nearby fat-tail observations into a single observation. This approach has been criticized as it removes information.
threshold analysis can be performed after an adjustment for autocorrelation has been made.
We will explore integration with dependent time-series models, but, as Taleb would likely argue, the autocorrelative effects are most abundantly experienced in the body, and the tails will have far greater influence on the payoff. So one may choose to ignore dependence structures and still get valuable results.