Characteristics¶
Defining the various characteristics of the CarBen and Phat distributions.
Density¶
Phat¶
The Phat distribution density is simply s weighted average of the constituent left and right CarBens.
Right CarBen¶
The density of the CarBen is a piecewise function as detailed by Carreau and Bengio.
Left CarBen¶
When reflected to the left-side, we simply flip the valence of the \(x\) and Pareto location, \(a\).
Cumulative Distribution Function¶
Phat¶
Like the PDF, the Cumulative Distribution Function (CDF) of the Phat distribution is just the weighted average of the component CDFs.
Right CarBen¶
The CDF of the CarBen is also piece-wise, expressed as follows for the right.
Thus, the CDF is simply the sum of the Gaussian and Pareto components.
Left CarBen¶
The formula for the left CarBen is only slight more complicated. As with the other functions, the CDF of the left CarBen is a summation of its components. The CDF is scaled left-to-right, so in the left instance the first component incorporated is the generalized Pareto. The Pareto tail is a reflected version of its right-tailed cousin, so the CDF of the left is equivalent to the survival function of the right. And we know the reflection is achieved by reversing the valence of \(a\) and \(x\).
And this handles the CDF up to the junction \(a\). Equal to and beyond \(a\), we must determine how to sum the CDF of Pareto and the Gaussian. When \(x=a\),
and
For the Gaussian, we must exclude the left-tail portion and so calculate the CDF on the interval \([a, x)\), which is equivalent to:
This results in:
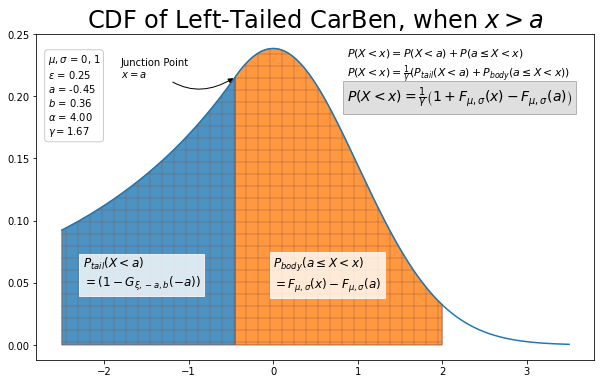
Putting the pieces together results in:
Quantile Function¶
Phat¶
Once again, the Quantile Function \(Q(.)\), known in scipy as the percent-point function, ppf, for the Phat distribution is a weighted average of the CarBens.
Right CarBen¶
Before we derive \(Q(x)\) for each CarBen, it is helpful to know the quantile of the junction point between the tail and body distributions. We know this point to be the location parameter, \(a\), of the generalized Pareto. We also know the relationship between the junction point and \(\gamma\). For the right CarBen,
Quantiles are, of course, merely the cumulative distribtion up to the given point. So the junction quantile, available via the qjunc method, is merely:
So, for the right-tailed CarBen, first remember the definition of the Quantile function:
where, in this framing, we refer to \(P(X\leq x)\) or \(F(x)\) as the quantile. One important difference between the Q derivation and the PDF/CDF derivations above is that the Q function is not a summation of the body and tail Q functions. Q(.) identifies a value derived specifically and solely from the distribution from which it originates. That means, for a right-tailed CarBen,
Remember, the input to the Quantile function is a cumulative probability for the entire piecewise, hybrid CarBen. So we must conver that probability, \(P(X<x)\), into \(P_{\textit{body}}(X<x)\) or \(P_{\textit{tail}}(X<x)\) to find the correct value.
So, for all \(x\),
Recall:
so, where \(x\leq a\),
and where \(x>a\),
So, for the right-tail CarBen, the Quantile function for a given \(q = P(X<x)\):
Left CarBen¶
As we’ve seen, the left-tailed CarBen requires slight modifications to the formulas. For the qjunc, remember that that CDF of the left-tailed Pareto is equivalent to the Survival Function of the right-tailed, with location, \(a\), reflected so:
again available via the qjunc method.
For the Quantile function, we rearrange the piecewise components as follows:
We want to express the target left-tailed x value and the Quantile function in terms of the right-tailed x and right Quantile function. This means:
Beginning again with, for all \(x\),
so, where \(x<a\),
And where \(x\geq a\), first, recall in the body,
We also know that,
So,
In the body, realize that \(x_{\textit{left}} = x_{\textit{right}}\)
The end results is:
Moments¶
Here we show how to find the moments of the Phat distribution. As we know, the Phat distribution is a mixture model of two Carben distributions, each weighted 50%. Thus, the PDF of the Phat distribution is simply:
The Carben distribution has a piecewise density function, defined for a right-tail as:
And for the left
The MGF for a mixture model is simply the weighted average of MGF’s of its components, shown as follows:
Thus, to find the moments of the Phat, we must find the MGFs of the component Carbens.
Carben Right¶
The MGF of a piecewise distribution is simply the sum of the integrals along the bounded ranges.
The body term is a truncated normal distribution. The moments of such functions are known and available in scipy. We know that the generalized Pareto is always restricted the interval \((a,\infty)\), so the tail term is merely the MGF of generalized Pareto scaled by \(\frac{1}{\gamma}\). Thus,
where: \(u\) is the upper bound of the body
Carben Left¶
Now for the left:
Once again, the tail portion is the MGF of the generalized Pareto. And once again, the body portion is a truncated normal, this time with a lower bound, so the MGF is found as:
where: \(l\) is the lower bound of the body
Mean¶
The first moment is the first derivative of \(M\), so:
In both instances, the constant multiplicative survives the differentiations. For the left tail, in order to reflect its true location, \(a\), we must invert the sign:
Finding mean of the Phat distribution programmatically is thus fairly trivial.
[12]:
import numpy as np
import scipy.stats as scist
import phat as ph
[13]:
phat = ph.Phat(.1, .2, .2, .25)
bmu = scist.truncnorm(
-np.inf,
phat.right.a,
*phat.right.body.args
).mean()
tmu = phat.right.tail.mean()
rmu = (bmu + tmu) / phat.right.gamma
bmu = scist.truncnorm(
phat.left.a,
np.inf,
*phat.left.body.args
).mean()
tmu = -phat.left.tail.mean()
lmu = (bmu + tmu) / phat.left.gamma
The mean of the Phat distribution is:
[14]:
np.mean((lmu, rmu))
[14]:
0.1426574558489754
We can see the mean of the Phat in the above example is close to, but slightly higher than the mean of the Gaussian body, \(\mu\). This results from the greater tail index in the right tail used in the example.
[15]:
phat.mean()
[15]:
0.1426574558489754
Variance¶
The second moment is the second derivative of \(M\), so:
Note that no negative is applied to the second moment as it eliminated bystanders the square.
And so the variance of the Phat is found as:
[16]:
bvar = scist.truncnorm(
-np.inf,
phat.right.a,
*phat.right.body.args
).var()
tvar = phat.right.tail.var()
rvar = (bvar + tvar) / phat.right.gamma
[17]:
bvar = scist.truncnorm(
phat.left.a,
np.inf,
*phat.left.body.args
).var()
tvar = phat.left.tail.var()
lvar = (bvar + tvar) / phat.left.gamma
[18]:
lvar
[18]:
0.4828404012432034
The variance for the Phat distribution is then:
[19]:
np.mean((lvar, rvar))
[19]:
0.5732923559721449
This is available as var method of the Phat distribution.
[20]:
phat.var()
[20]:
0.5732923559721449