What Are Fat Tails?¶
Here we discuss some of the theoretical underpinnings of fat-tail distributions, informed mainly by Nassim Taleb in SCOFT.
Thin vs. Fat¶
Probabliity distributions range from thin-tailed to fat-tailed. Taleb formally defines a fat-tailed distribution as a distribution where the tail events dominate its characteristics and impacts. Others refer to this root class as “heavy” tails, reserving “fat” tails for the most dramatic subset.
Taleb suggests “subexponential” distributions as the borderline between thin and fat tails, which are defined in terms of the slope of their survival functions in the tails: + the slope of thin-tailed survivial functions (such as the Guassian) decay exponentially towards \(\infty\), usually towards some upper bound evident on a log-log plot. + the slope of heavy-tailed survival functions decay at a rate slower than exponential, at a minimum, with the more dramatic fat tails decaying linearily (or not decaying at all). + Subexponential distributions will have a kurtosis > 3 (kurtosis of Gaussian)
The Borderline Sigmoid¶
Taleb defines the borderline distribution between thin and fat where the ratio of the power over the root is 1 for a two-tailed distribution:
A sample of such a distribution is suggested as:
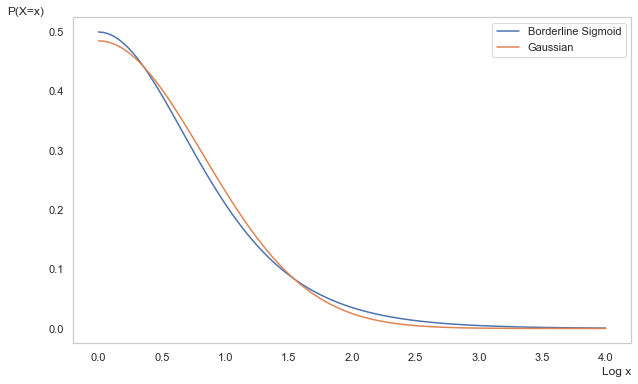
The kurtosis of the above distribution is 4.2, which is greater than 3 (the kurtosis of the standard Gaussian), and so it has slightly fatter tails.
This distribution is available in the package as BLineSigmoid. In the figure below, we can see the slightest difference in the head, shoulders, and tail versus the Gaussian.
[2]:
import numpy as np
import scipy.stats as scist
import matplotlib.pyplot as plt
import phat as ph
k = 1
x = np.linspace(0,4,100)
bline = ph.dists.BLineSig(k)
norm = scist.norm(scale=bline.var())
fig, ax = plt.subplots(1,1,figsize=(10,6))
ax.plot(x, bline.pdf(x), label='Borderline Sigmoid')
ax.plot(x, norm.pdf(x) , label='Gaussian')
ax.set_ylabel('P(X=x)', loc='top', rotation='horizontal')
ax.set_xlabel('Log x', loc='right')
plt.legend()
ax.grid(False)
plt.show()
The Devil is in the Tails¶
So a distribution need only have kurtosis > 3 to be classified as fat-tailed (at least by Taleb). But we can further distinguish between fat tails by the change in slope of the tail as \(n\to\infty\). This slope is referred to as the “tail index”, designated \(\alpha\) by Taleb (and many other greeks by various others).
Thin tails such as the Gaussian have non-linear tails whose slopes decay towards infinity, i.e. \(\alpha\to\infty\) as \(n\to\infty\), meaning the distributions reach an effective maximum. At this level, E(X | X > x) = X, meaning there are no values \(> x\) expected in the distribution.
The more dramatic fat tails tend to a non-zero, non-infinite slope, meaning they have no effective maximum. These include the Power Laws. The Power Laws also result in other strange characteristics such as undefined moments including undefined variance (\(\alpha < 2\)) and undefined mean (\(\alpha < 1\)).
Below we show log-log scales of the Gaussian thin tail versus two subexponential distributions (each with tail index \(\alpha = 3\)).
the Lognormal, which is a fat tail masquerading as a power law and is revealed as an imposter at larger \(x\).
the Student’s T, which is often used as a power law, though it only tends to one at larger \(x\).
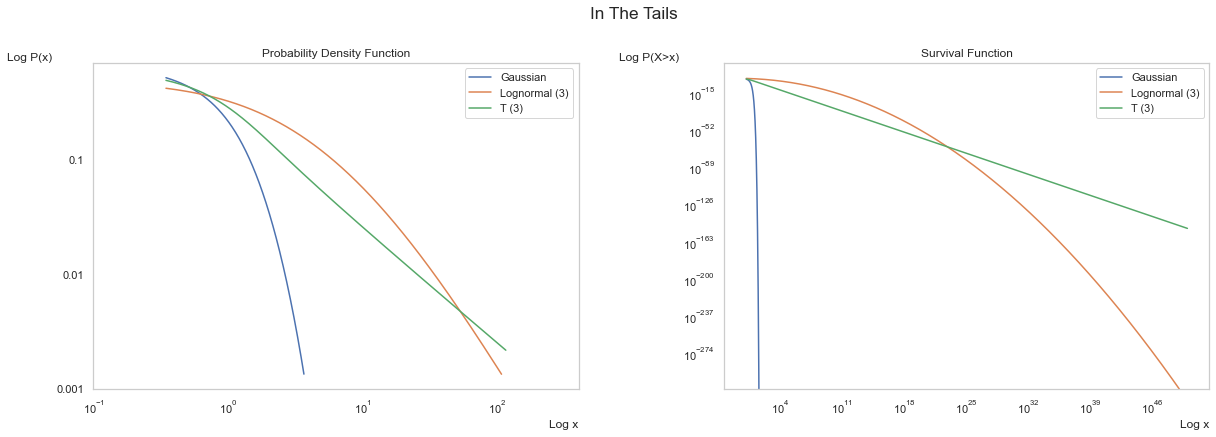
First, above, we see the PDF of the three distributions with the Gaussian evidencing exponential decay almost immediately, the lognormal decaying into the tails, and the T distribution becoming linear further into the tails. The Survival Function accentuates the difference.
Scale Invariance¶
The property of a linear slope in the tails of a distribution is known as “scale invariance” (again see SCOFT). It means that for a scalar increase in \(x\), the probability of occurence decays at a constant rate. Thin-tailed and non-power law fat tails are “scale variant”, meaning that the probability of occurence decays at an increasing rate.
This is a remarkably powerful effect, as outcomes far out in the tails of power laws are orders of magnitude of orders of magnitude (not a typo) more likely. This is not to say that tail events will occur more often; instead it means that when tail events do occur, they will be much larger.
This impact is most readily seen when we decrease the tail index, thereby decreasing the rate of (linear) decay of the survival function, and watch the impact on the first and second moments.
[12]:
import pandas as pd
alphas = pd.Index([3,2,1], name=r'$\alpha$')
chars = [(scist.pareto(alpha).mean(), scist.pareto(alpha).var()) for alpha in alphas]
df = pd.DataFrame(chars, columns=[r'$\mu$', r'$\sigma^2$'], index=alphas)
df
[12]:
| $\mu$ | $\sigma^2$ | |
|---|---|---|
| $\alpha$ | ||
| 3 | 1.5 | 0.75 |
| 2 | 2.0 | inf |
| 1 | inf | inf |
With a tail index of 2, the potential for extreme values makes the variance undefined. With a tail index of 1 extreme values can be so large that the distribution has no mean.
Scale invariance is mathematically defined as:
where \(L(x)\) is a slow-varying function defined as:
\(L(x)\) can simply be replaced with a constant, as per the Pareto distribution:
We can see this property of scale invariance most clearly in the table below, where we compare the Gaussian, Lognormal, T, Pareto, and the LogPareto scale ratios at increaseing \(k\). This is an expanded version of the table found SCOFT.
[5]:
import pandas as pd
def tail_scale(p, dist):
return dist.sf(p[1]) / dist.sf(p[0]*p[1])
norm = scist.norm()
lg = scist.lognorm(2)
t = scist.t(2)
pareto = scist.pareto(2)
lp = ph.dists.LogPareto(2)
dists = [norm, lg, t, pareto, lp]
n = [i for i in range(1,5)]
k = [i for i in range(2,16,2)]
index = pd.MultiIndex.from_product([n, k], names=['n', 'k'])
l1 = ['Gaussian', 'Lognorm (2)', "T (2)", 'Pareto (2)', 'Logpareto (2)']
l2 = [r'$P(X > k)^{-1}$', r'$\frac{P(X > k)}{P(X > nk)}$']
cols = pd.MultiIndex.from_product((l1,l2))
distcomp = pd.DataFrame([], index=index, columns=cols)
distcomp = distcomp.sort_values(['n', 'k'])
with np.errstate(divide='ignore'):
for dist, l in zip(dists, l1):
distcomp.loc[:, (l, l2[0])] = [1 / dist.sf(p[1]) for p in index]
distcomp.loc[:, (l, l2[1])] = [tail_scale(p, dist) for p in index]
cols_arr = np.array([[j for j in i] for i in distcomp.columns.to_numpy()])
fmt1 = {tuple(col): "{:,.0E}" for col in distcomp.columns[:2]}
fmt2 = {tuple(col): "{:,.0f}" for col in distcomp.columns[[4, 6, 7]]}
fmt3 = {tuple(col): "{:,.1f}" for col in distcomp.columns[[5, 8, 9]]}
distcomp.style.format({**fmt1, **fmt2, **fmt3})
[5]:
| Gaussian | Lognorm (2) | T (2) | Pareto (2) | Logpareto (2) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| $P(X > k)^{-1}$ | $\frac{P(X > k)}{P(X > nk)}$ | $P(X > k)^{-1}$ | $\frac{P(X > k)}{P(X > nk)}$ | $P(X > k)^{-1}$ | $\frac{P(X > k)}{P(X > nk)}$ | $P(X > k)^{-1}$ | $\frac{P(X > k)}{P(X > nk)}$ | $P(X > k)^{-1}$ | $\frac{P(X > k)}{P(X > nk)}$ | ||
| n | k | ||||||||||
| 1 | 2 | 4E+01 | 1E+00 | 2.743817 | 1.000000 | 11 | 1.0 | 4 | 1 | 0.5 | 1.0 |
| 4 | 3E+04 | 1E+00 | 4.096537 | 1.000000 | 35 | 1.0 | 16 | 1 | 1.9 | 1.0 | |
| 6 | 1E+09 | 1E+00 | 5.400778 | 1.000000 | 75 | 1.0 | 36 | 1 | 3.2 | 1.0 | |
| 8 | 2E+15 | 1E+00 | 6.700849 | 1.000000 | 131 | 1.0 | 64 | 1 | 4.3 | 1.0 | |
| 10 | 1E+23 | 1E+00 | 8.012438 | 1.000000 | 203 | 1.0 | 100 | 1 | 5.3 | 1.0 | |
| 12 | 6E+32 | 1E+00 | 9.342767 | 1.000000 | 291 | 1.0 | 144 | 1 | 6.2 | 1.0 | |
| 14 | 1E+44 | 1E+00 | 10.695620 | 1.000000 | 395 | 1.0 | 196 | 1 | 7.0 | 1.0 | |
| 2 | 2 | 4E+01 | 7E+02 | 2.743817 | 1.493007 | 11 | 3.2 | 4 | 4 | 0.5 | 4.0 |
| 4 | 3E+04 | 5E+10 | 4.096537 | 1.635735 | 35 | 3.7 | 16 | 4 | 1.9 | 2.2 | |
| 6 | 1E+09 | 6E+23 | 5.400778 | 1.729893 | 75 | 3.9 | 36 | 4 | 3.2 | 1.9 | |
| 8 | 2E+15 | 1E+42 | 6.700849 | 1.801732 | 131 | 3.9 | 64 | 4 | 4.3 | 1.8 | |
| 10 | 1E+23 | 3E+65 | 8.012438 | 1.860442 | 203 | 4.0 | 100 | 4 | 5.3 | 1.7 | |
| 12 | 6E+32 | 1E+94 | 9.342767 | 1.910407 | 291 | 4.0 | 144 | 4 | 6.2 | 1.6 | |
| 14 | 1E+44 | 1E+128 | 10.695620 | 1.954086 | 395 | 4.0 | 196 | 4 | 7.0 | 1.6 | |
| 3 | 2 | 4E+01 | 2E+07 | 2.743817 | 1.968345 | 11 | 6.9 | 4 | 9 | 0.5 | 6.7 |
| 4 | 3E+04 | 2E+28 | 4.096537 | 2.280650 | 35 | 8.3 | 16 | 9 | 1.9 | 3.2 | |
| 6 | 1E+09 | 1E+63 | 5.400778 | 2.495302 | 75 | 8.7 | 36 | 9 | 3.2 | 2.6 | |
| 8 | 2E+15 | 4E+111 | 6.700849 | 2.663616 | 131 | 8.8 | 64 | 9 | 4.3 | 2.3 | |
| 10 | 1E+23 | 2E+174 | 8.012438 | 2.804049 | 203 | 8.9 | 100 | 9 | 5.3 | 2.2 | |
| 12 | 6E+32 | 4E+250 | 9.342767 | 2.925584 | 291 | 8.9 | 144 | 9 | 6.2 | 2.1 | |
| 14 | 1E+44 | INF | 10.695620 | 3.033336 | 395 | 8.9 | 196 | 9 | 7.0 | 2.0 | |
| 4 | 2 | 4E+01 | 4E+13 | 2.743817 | 2.442164 | 11 | 12.0 | 4 | 16 | 0.5 | 9.0 |
| 4 | 3E+04 | 5E+52 | 4.096537 | 2.947156 | 35 | 14.7 | 16 | 16 | 1.9 | 4.0 | |
| 6 | 1E+09 | 7E+117 | 5.400778 | 3.304799 | 75 | 15.4 | 36 | 16 | 3.2 | 3.1 | |
| 8 | 2E+15 | 1E+209 | 6.700849 | 3.590865 | 131 | 15.7 | 64 | 16 | 4.3 | 2.8 | |
| 10 | 1E+23 | INF | 8.012438 | 3.833161 | 203 | 15.8 | 100 | 16 | 5.3 | 2.6 | |
| 12 | 6E+32 | INF | 9.342767 | 4.045406 | 291 | 15.8 | 144 | 16 | 6.2 | 2.4 | |
| 14 | 1E+44 | INF | 10.695620 | 4.235510 | 395 | 15.9 | 196 | 16 | 7.0 | 2.3 | |
Focusing on the \(\frac{P(X>k)}{P(X>nk}\) column, we can see dramatic differences between the distributions:
Pareto: For each
n, the value ofkhas no impact on the ratio. It is stable, regardless of the value ofkused. This is the “scale invariance” described above.Gaussian: the complete opposite occurs, with the ratio exploding higher for minor increments of
k.Lognormal / Student’s T: the ratio for both increases much slower than the Gaussian, but still does not reach a stable value until deep into the tails. Hence, the drawback of using Student’s T as a substitute for power laws and why significant literature has been devoted to use of the generalized Pareto. We can see this visually below.
[6]:
x = np.logspace(.2, 2, 100000, dtype=np.float64)
t = scist.t(3)
pareto = scist.pareto(3)
gp = scist.genpareto(1/3)
convergence = np.isclose(t.sf(x), pareto.sf(x), atol=0.000001).argmax()
fig, ax2 = plt.subplots(1,1,figsize=(10,6))
ax2.plot(x, t.sf(x), label='T (3)')
ax2.plot(x, gp.sf(x), label='GenPareto (3)')
ax2.plot(x, pareto.sf(x), label='Pareto (3)')
ax2.scatter(
x[convergence],
t.sf(x[convergence]),
c='C3', marker='x', alpha=1,
label='Convergence'
)
ax2.set_xscale('log')
ax2.set_yscale('log')
ax2.set_ylabel('Log P(X>x)', loc='top', rotation='horizontal')
ax2.set_xlabel('Log x', loc='right')
ax2.legend()
ax2.grid(False)
plt.show()
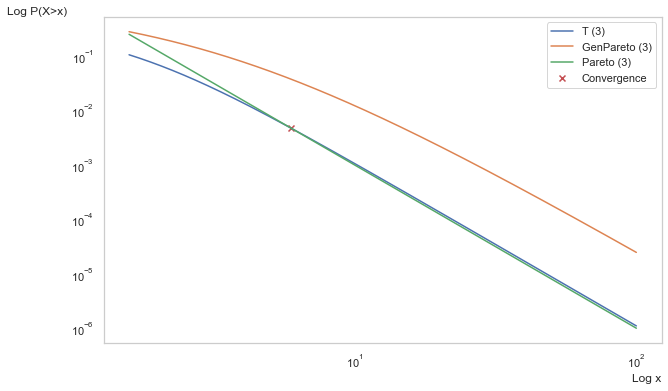
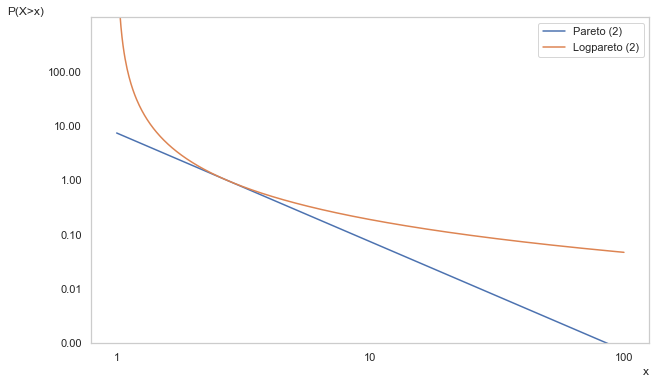
meanwhile, the LogPareto is not only scale invariant at large \(k\), it is also invariant to \(n\)!!! Or at least it tends there over time. This means as \(\alpha\to0\) as \(x\to\infty\), which can be seen below.
Six Sigma is Not Six Sigma¶
The impact of fat tails is readily observable in daily equity returns. In a Gaussian distribtion, a “Six Sigma” event (i.e. one that is 6 standard deviations from the mean) should occur two in every \(10^9\) samples. For daily equity returns, this translates into a Six Sigma event occuring every ~4 million years. By contrast, a Six Sigma event in the Pareto should occur once every 36 days.
[13]:
n_years_gauss = (1 / scist.norm.sf(6)) / 252
n_days_pareto = (1/scist.pareto(2).sf(6))
print (f'Guassian: {n_years_gauss:,.0f} years')
print (f'Pareto: {n_days_pareto:.0f} days')
Guassian: 4,022,201 years
Pareto: 36 days
We are fed Black-Sholes and Guassian-based volatility for option pricing for much of our lives. And yet if you are just 10 years old, you’ve lived long enough to see a Six Sigma event in the US equity market. And if you’ve lived 80 years, well …
Below we show the occurrences of Six Sigma events in the S&P 500 over various timeframes. Each time the blue line breaches the red dotted line, that is a 2-in-4M year occurence according to the Gaussian.
[10]:
import yfinance as yf
sp = yf.download('^GSPC')
sp_ret = sp.Close.pct_change()[1:]
[*********************100%***********************] 1 of 1 completed
[11]:
from datetime import datetime as dt
fig, axs = plt.subplots(2,2, figsize=(18,14))
axs = axs.flatten()
rngs = np.arange(30, 0, -10)
rngs = np.concatenate(([90], rngs))
titles = [f'Sigma over {rng} Year TimeFrames' for rng in rngs]
for i in range(4):
sp_ret.plot(ax=axs[i])
yrs = np.arange(sp_ret.index.min().year, sp_ret.index.max().year, rngs[i])
yrs = np.array([dt(yr, 1, 1) for yr in yrs])
ranges = np.vstack((yrs[:-1], yrs[1:])).T
stds = []
for rng in ranges:
sp_split = sp_ret[slice(*rng)]
mean, std = scist.norm.fit(sp_split)
stds.append(std)
cum = np.concatenate((np.zeros(1), np.repeat(1 / len(stds), len(stds)).cumsum()))
trng = np.vstack((cum[:-1], cum[1:])).T
for j in range(len(stds)):
sig = axs[i].axhline(stds[j]*6, *trng[j], c='C3', ls='--', lw=1, label=r'$6\sigma$')
signeg = axs[i].axhline(-stds[j]*6, *trng[j], c='C3', ls='--', lw=1, label=r'$-6\sigma$')
axs[i].set_xlabel('')
axs[i].set_ylabel('Daily Returns')
axs[i].legend(handles=[sig])
axs[i].set_title(titles[i])
plt.show()
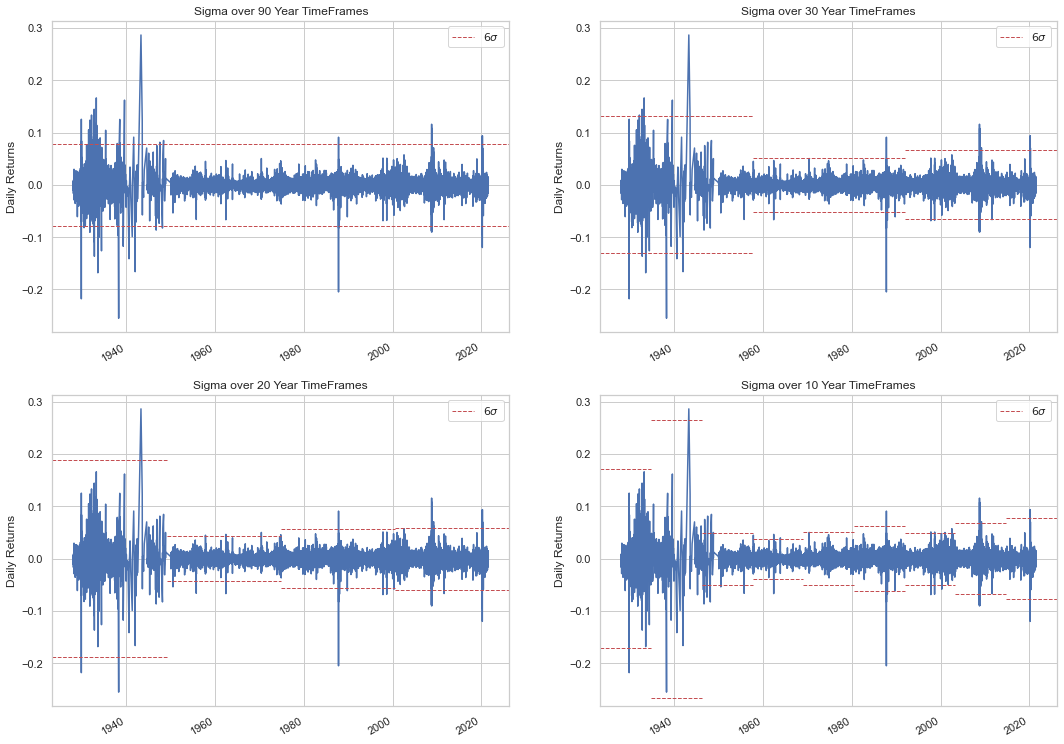
To paraphrase Taleb:
If you see a 6 sigma event, that’s not a 6 sigma event.
Daily equity returns are clearly not Gaussian, which has one major implication: Geometric Brownian Motion is not appropriate for share prices and by extension the Black-Scholes pricing model is utterly invalid.